Python Data Science Online Test
For jobseekers
Practice your skills and earn a certificate of achievement when you score in the top 25%.
Take a Practice TestFor companies
Screen real Python Data Science skills, flag human or AI assistance, and interview the right people.
About the test
The Python Data Science online test assesses knowledge of using Python and data science libraries such as Pandas, NumPy, Scipy, and Scikit-learn to analyze data through a series of live coding questions. This test requires applying probability and statistics to solve data science problems.
The assessment includes work-sample tasks such as:
- Classification of data using different algorithms.
- Aggregating, grouping, sorting, and cleaning data.
- Building machine learning models.
A good data scientist or data analyst using Python for their tasks should be able to take advantage of the functionality provided by Python data science libraries to extract and analyze knowledge and insights from data.
Sample public questions
You are given a list of tickers and their daily closing prices for a given period.
Implement the most_corr function that, when given each ticker's daily closing prices, returns the pair of tickers that are the most highly (linearly) correlated by daily percentage change.
A company stores login data and passwords in two different containers:
- DataFrame with columns: Id, Login, Verified.
- Two-dimensional NumPy array where each element is an array that contains: Id and Password.
Elements on the same row/index have the same Id.
Implement the function login_table that accepts these two containers and modifies id_name_verified DataFrame in-place, so that:
- The Verified column should be removed.
- The password from NumPy array should be added as the last column with the name "Password" to DataFrame.
For example, the following code snippet:
id_name_verified = pd.DataFrame([[1, "JohnDoe", True], [2, "AnnFranklin", False]], columns=["Id", "Login", "Verified"])
id_password = np.array([[1, 987340123], [2, 187031122]], np.int32)
login_table(id_name_verified, id_password)
print(id_name_verified)Should print:
Id Login Password 0 1 JohnDoe 987340123 1 2 AnnFranklin 187031122
For jobseekers: get certified
Earn a free certificate by achieving top 25% on the Python Data Science test with public questions.
Take a Certification TestSample silver certificate
Sunshine Caprio
Java and SQL TestDomeCertificate

For companies: premium questions
Buy TestDome to access premium questions that can't be practiced.
Ready to interview?
Use these and other questions from our library with our
Code Interview Platform.
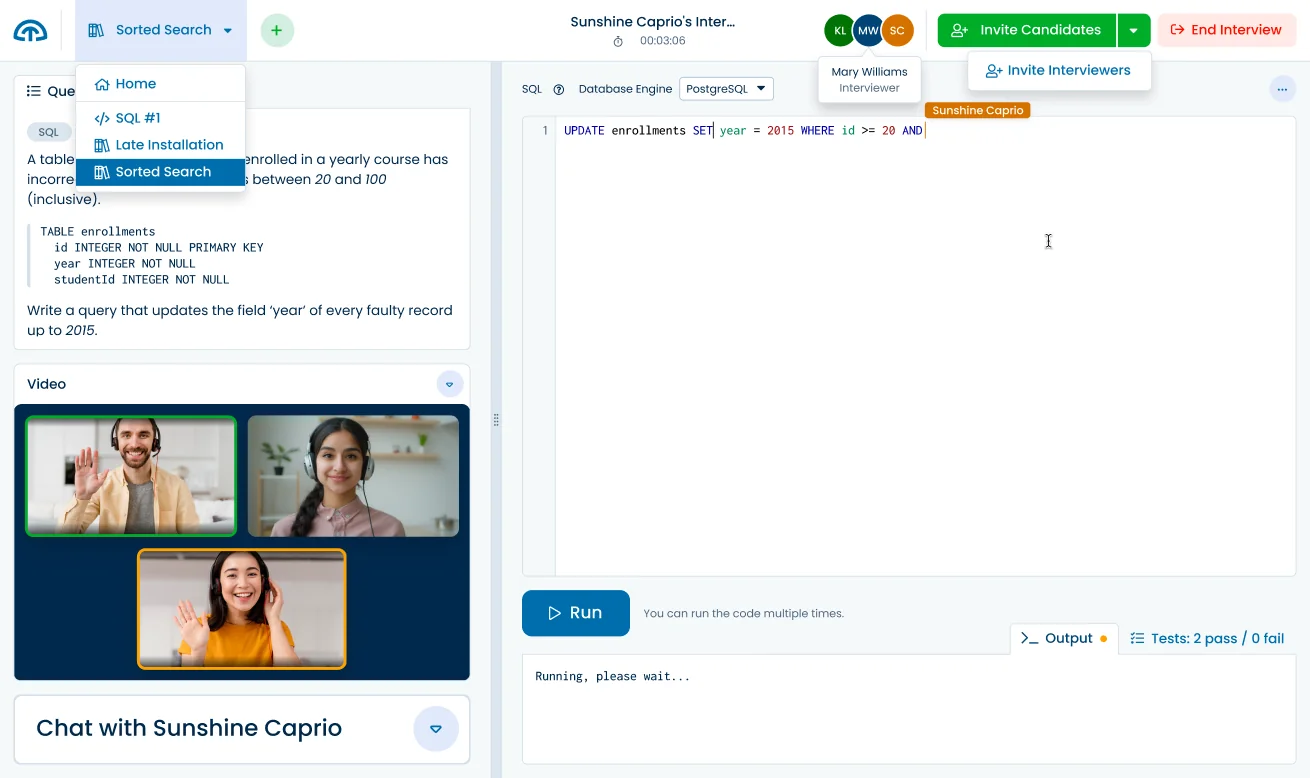
7 more premium Python Data Science questions
Class Grades, Birthday Cards, Free Throws, Distribution Fitting, Clean CSV, Median Height, Fill Median.
Skills and topics tested
- Python for Data Science
- Grouping
- NumPy
- Pandas
- Sorting
- Data Aggregation
- Cauchy Distribution
- Exponential Distribution
- Normal Distribution
- SciPy
- Data Cleaning
- Processing CSV
- Median
For job roles
- Data Analyst
- Data Scientist
- Statistician
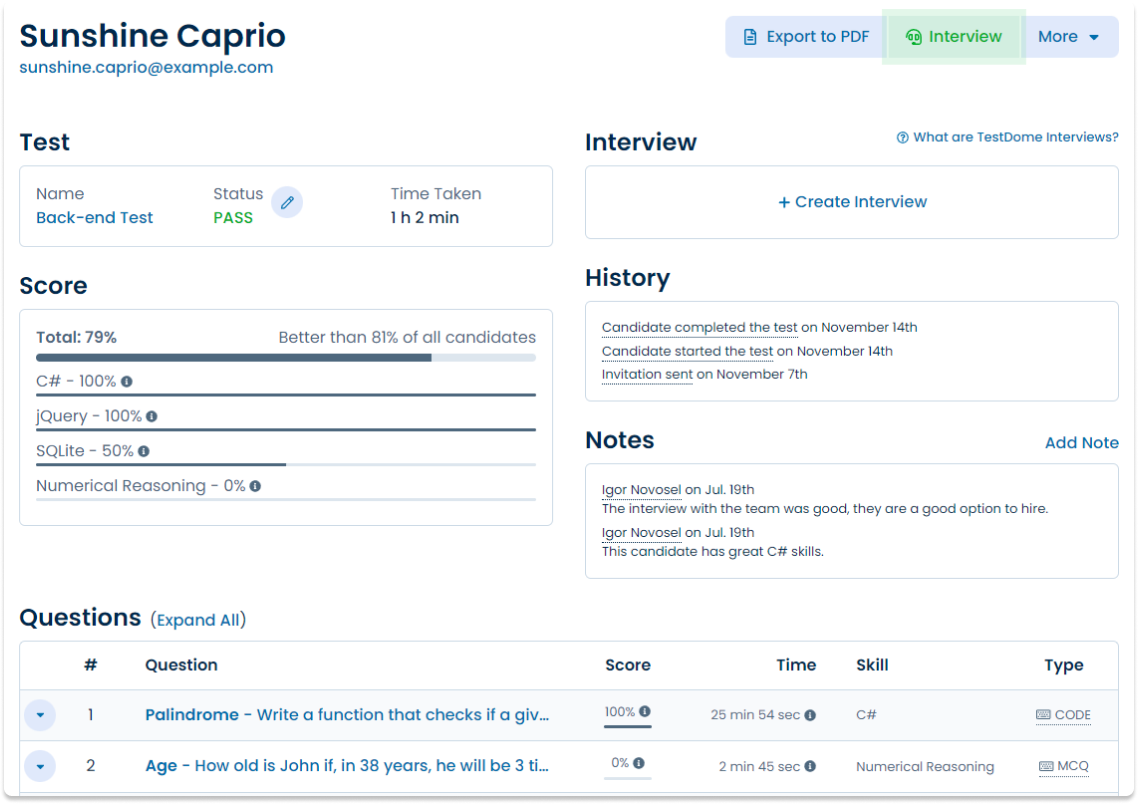
Sample candidate report
Need it fast? AI-crafted tests for your job role
TestDome generates custom tests tailored to the specific skills you need for your job role.
Sign up now to try it out and see how AI can streamline your hiring process!
What others say

Simple, straight-forward technical testing
TestDome is simple, provides a reasonable (though not extensive) battery of tests to choose from, and doesn't take the candidate an inordinate amount of time. It also simulates working pressure with the time limits.
Jan Opperman, Grindrod Bank
Product reviews



Used by




Solve all your skill testing needs
150+ Pre-made tests
130+ skills
AI-ready assessments
How TestDome works
Choose a pre-made test
or create a custom test
Invite candidates via
email, URL, or your ATS
Candidates take
a test remotely
Sort candidates and
get individual reports